반응형
SQL Joins
2개 이상의 테이블을 1개의 테이블로 생각하고 join하여 쿼리를 날리는 것
⇒ 두개이상의 테이블이나 데이터베이스를 연결하여 데이터를 검색하는 방법
- 보통 Primary key혹은 Foreign key로 두 테이블을 연결
- 테이블을 연결하려면 적어도 하나의 칼럼은 서로 공유되어야 한다.
Inner join
= intersect
- 교집합의 느낌이다.
- A 테이블과 B 테이블이 모두 가지고있는 데이터만 검색

SELECT Column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column_name;SELECT 테이블별칭.조회할칼럼,
테이블별칭.조회할칼럼
FROM 기준테이블 별칭
INNER JOIN 조인테이블 별칭
ON 기준테이블별칭.기준키 =
조인테이블별칭.기준키Outer join
Left Outer join
- 기준테이블의 값(table1) + 테이블과 기준테이블의 중복된 값(table1과 2의 중복된 값)
- 테이블1의 모든 데이터 + 테이블1과 테이블2의 중복되는 값이 검색

SELECT Column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;Right Outer join
- 결과값은 테이블2의 모든 데이터와 + 테이블1과 테이블2의 중복되는 값
SELECT Column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name = table2.column_name;SELECT 테이블별칭.조회할칼럼,
테이블별칭.조회할칼럼
FROM 기준테이블 별칭
RIGHT OUTER JOIN 조인테이블 별칭
ON 기준테이블별칭.기준키 =
조인테이블별칭.기준키Full Outer join (== Full join)
- 그냥 합집합이라고 생각하면 됨
- 모든 데이터
SELECT Column_name(s)
FROM table1
full OUTER JOIN table2
ON table1.column_name = table2.column_name
WHERE CONDITION;SELECT 테이블별칭.조회할칼럼,
테이블별칭.조회할칼럼
FROM 기준테이블 별칭
FULL OUTER JOIN 조인테이블 별칭
ON 기준테이블별칭.기준키 =
조인테이블별칭.기준키Self join
- 하나의 테이블을 여러번 복사해서 join
- 자기 자신 테이블과 join
- FROM 뒤에 테이블이 두 개가 온다는 것이 self join 의 특징 / 하나의 테이블 이름을 다르게 지정해줘야 함
SELECT Column_name(s)
FROM table1 T1,
table1 T2
WHERE CONDITION;Cross join

- 모든 경우의 수를 표현할 때 사용
- A, B 테이블이 있을 때 A 테이블의 한 행을 B테이블의 모든 행과 비교할 때
- 결과값이 엄청 많아짐 (n * m)
--방법1--
SELECT A.NAME,
B.age
FROM ex_table A
CROSS JOIN join_table--방법2--
SELECT A.NAME,--A테이블의 NAME조회
B.age --B테이블의 AGE조회
FROM ex_table A,
join_table B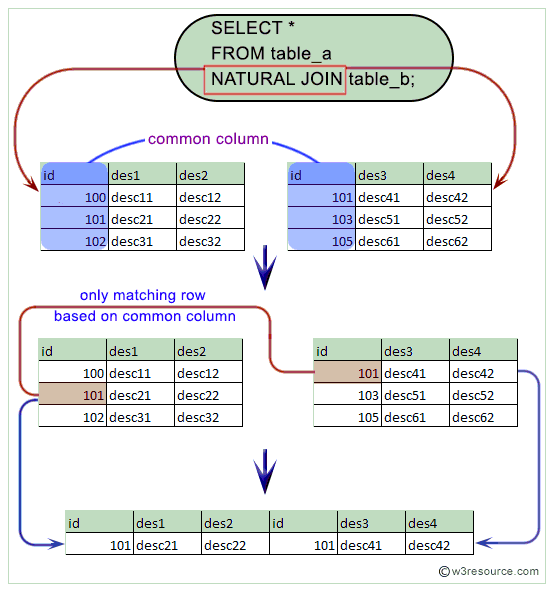
Natural join
- NATURAL JOIN은 두 테이블의 동일한 이름을 가지는 칼럼이 모두 조인된다.
- 반드시 두 테이블 간의 동일한 이름, 타입을 가진 컬럼이 필요하다.
- 동일한 이름을 갖는 컬럼이 있지만 데이터 타입이 다르면 에러가 발생한다.
- 반드시 두 테이블 간의 동일한 이름, 타입을 가진 컬럼이 필요하다.
- USING 절을 사용해서 특정 칼럼을 설정해서 사용 가능
- 동일한 칼럼을 내부적으로 찾게 되므로 테이블 별칭(Alias)을 주면 오류가 발생한다.
- 조인하는 테이블 간의 동일 컬럼이 SELECT절에 기술되도 테이블 이름을 생략해야 한다.
- 조인에 이용되는 컬럼은 명시하지 않아도 자동으로 조인해 사용된다.
SELECT 컬럼,
컬럼,
…
FROM 테이블1
Natural JOIN 테이블2 [NATURAL JOIN 테이블3] …
WHERE 검색 조건;Group by
.png)
- 테이블의 레코드를
grouping하기 위해 사용 - 국가, 성별 같이 같은 값을 가진 카테고리별로 묶어서 조회
- aggregate functions <집계 함수> (COUNT(), MAX(), MIN(), SUM(), AVG())와 함께 자주 사용됩니다.
SELECT Column_name(s)
FROM table_name
WHERE CONDITION
GROUP BY Column_name(s)
ORDER BY Column_name(s);SELECT Count(customerid),
country
FROM customers
GROUP BY country
ORDER BY Count(customerid) DESC; *-- count 기준으로 orderby 내림차순*Having
.png)
- WHERE 절이 aggregate function (sum같은) 과 같이 사용될 수 없어서 추가됨
- GROUP BY 하위에 조건을 걸 때 사용 , ORDER BY 위에
- Where 절 뒤에 Like 구문을 넣는것과 having 절에 Like 구문을 넣는것은 동일하다.
SELECT Count(customerid),
country
FROM customers
GROUP BY country
HAVING Count(customerid) > 5
ORDER BY Count(customerid) DESC;집합연산자와 서브쿼리
.png)
UNION
- 중복을 제거한 결과의 합
- 중복데이터는 출력되지 않음
- 두 개 이상의 SELECT문과 결과값을 결합하는데 사용
- JOIN과 유사하지만 SELECT 문으로 만들어진 field가 동일한 데이터 유형에 사용되어야 함
.png)
- UNION 내 SELECT문의 결과값은 같은 수의 열을 가지고 동일한 순서로 있어야 함
SELECT column_name(s)
FROM table1
UNION
SELECT column_name(s)
FROM table2;
SELECT city,
country
FROM customers
WHERE country = 'Germany'
UNION
SELECT city,
country
FROM suppliers
WHERE country = 'Germany'
ORDER BY city;UNION ALL
- 중복을 포함한 결과의 합
- UNION 은 중복값을 출력하지 않기 때문에 중복값까지 모두 출력할 때 사용
SELECT column_name(s)
FROM table1
UNION ALL
SELECT column_name(s)
FROM table2;INTERSECT
.png)
- 양쪽 모두에서 포함된 행
- INTERSECT는 두 SELECT문을 결합하는 데 사용되지만 두 번째 SELECT문의 행과 동일한 첫 번째 SELECT 문의 행만 반환
- 두 개의 SELECT 문에서 반환된 공통 행만 반환
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
INTERSECT
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]SELECT id
FROM a
INTERSECT
SELECT id
FROM b;EXCEPT
- 굳이 안써도 됨
- = MINUS
- 첫 번째 검색 결과에서 두 번째 검색 결과를 제외한 나머지
.png)
- 보통 EXCEPT 집합연산자를 이용한 방법보다 두 개의 조건을 이용한 SELECT문이 훨씬 단순하고 가독성이 좋으며 성능 또한 우수
- 경우에 따라 EXCEPT 연산자를 이용하면 성능이 훨씬 좋을 때가 있음 (ex. 조건에 부정연산이 들어간 경우)
SELECT employee_id,
last_name,
job_id
FROM employees
WHERE last_name LIKE 'K%'
AND job_id != 'SA_REP';
-- 이게 가독성이 더 좋고 성능이 더 우수함 SELECT employee_id,
last_name,
job_id
FROM employees
WHERE last_name LIKE 'K%'
EXCEPT
SELECT employee_id,
last_name,
job_id
FROM employees
WHERE job_id = 'SA_REP';- 서브쿼리
- 집합연산자와 서브쿼리 = ANY연산
- 집합연산자와 서브쿼리 = ALL연산
- 집합연산자와 서브쿼리 = EXISTS연산
.png)
📌 Sub-query란 ?
- 하나의 SQL 문에 포함되어 있는 또 다른 SQL 문
- SELECT문 내의 또다른 SELECT문 같은거
📌 Sub-query 사용시 주의사항
- 서브쿼리를 괄호로 감싸서 사용한다.
- 서브쿼리는 단일 행 또는 복수 행 비교 연산자와 함께 사용 가능하다.
- 서브쿼리에서는 ORDER BY 를 사용하지 못한다. ㅠㅠ
📌 Sub-query 가 사용 가능한 곳
- SELECT 절 FROM 절 WHERE 절
- HAVING 절 ORDER BY 절 - Groupby X
- INSERT 문의 VALUES 절
- UPDATE 문의 SET 절
📌 Sub-query의 예시
-- '이순신' 의 데이터를 가져오되 그 부서의 평균 연봉을 가져오라.
-- 출처: https://aljjabaegi.tistory.com/14 [알짜배기 프로그래머]
SELECT T1.*,
(SELECT Avg(salary)
FROM amt_mst_test S1
WHERE S1.dept_cd = T1.dept_cd) AS AVG_SALARY
FROM amt_mst_test T1
WHERE T1.emp_nm = '이순신'
.png)
- 위에서 AVG라는 그룹 함수를 사용하는 경우 결과값이 1건이기 때문이 단일 행 서브쿼리로써 사용 가능
- 서브쿼리가 단일 행 비교 연산자(=, <, <=, >, >=, <>)와 함께 사용할 때는 서브쿼리의 결과 건수가 반드시 1건 or 0건 이여야 합니다.
- 만약 결과가 2건 이상인 경우 오류가 발생
- 2건 이상인 경우 = 이 아닌 IN 을 사용해야 합니다.
-- '이순신' 의 데이터를 가져오되 그 부서의 평균 연봉을 가져오라.
-- 출처: https://aljjabaegi.tistory.com/14 [알짜배기 프로그래머]
SELECT T1.*,
(SELECT Avg(salary)
FROM amt_mst_test S1
WHERE S1.dept_cd = T1.dept_cd) AS AVG_SALARY
FROM amt_mst_test T1
WHERE T1.emp_nm IN '이순신'
SELECT c1,
c2,
c3
FROM t1
WHERE c1 IN (SELECT c1 -- Where 조건문에 IN을 사용한다.
FROM t2
WHERE c2 = '3')🥕 다중 칼럼 서브쿼리
- 서브쿼리 결과로 여러 개의 컬럼이 반환되어 메인쿼리의 조건과 동시에 비교되는 것을 의미함
- 서브쿼리의 결과가 여러 칼럼인 경우 다중 컬럼 서브쿼리라고 한다.
- 메인쿼리 WHERE절과 서브쿼리에서 반환하는 컬럼의 수가 반드시 같아야 한다.
- 아래의 예처럼 2개의 컬럼(부서번호, sal의 최솟값)을 반환하는 서브쿼리를 사용할 경우 WHERE절에도 2개의 컬럼명을 적어주고 괄호로 묶어준다.
-- 형태
SELECT c1,
c2,
c3
FROM t1
WHERE ( c1, c2 ) IN (SELECT c1,
c2
FROM t2
WHERE c2 = '3')
-- 괄호는 t2 테이블에서 c2값이 3인 c1c2컬럼을 가져와라 -- 부서별로 가장 작은 급여(sal)를 받는 직원을 조회
SELECT deptno,
ename,
sal
FROM emp
WHERE ( deptno, sal ) IN (SELECT deptno,
Min(sal)
FROM emp
GROUP BY deptno)
ORDER BY deptno;🥕 연관 서브쿼리
- 서브쿼리 내에 메인쿼리 컬럼이 사용된 서브쿼리 입니다.
- 메인쿼리의 값을 서브쿼리가 사용하고, 서브쿼리의 값을 받아서 메인쿼리가 계산하는 구조의 쿼리
- 메인쿼리의 값을 서브쿼리에 주고 서브쿼리를 수행한 다음
- 그 결과를 다시 메인쿼리로 반환해서 수행하는 쿼리
SELECT ename,
sal,
deptno
FROM emp
ORDER BY deptno,
sal;
ENAME sal deptno
-------------------- ---------- ----------
miller 1300 10
clark 2450 10
king 5000 10
smith 800 20
adams 1100 20
jones 2975 20
scott 3000 20
ford 3000 20
james 950 30
martin 1250 30
ward 1250 30
turner 1500 30
allen 1600 30
blake 2850 30
14 개의 행이 선택되었습니다.
------------------------------------------------------------
-- 부서별 평균 sal
SELECT deptno,
Avg(sal)
FROM emp
GROUP BY deptno;
DEPTNO avg(sal)
------------------------------------------------------------
30 1566.66667
20 2175
10 2916.66667
---------------------------------------------------------------------------
SELECT ename,
deptno,
sal
FROM emp e1
WHERE sal >
(
SELECT avg(sal)
FROM emp e2
WHERE e2.deptno=e1.deptno)
ORDER BY deptno;
ENAME deptno sal
------------------------------------------------------------
king 10 5000
jones 20 2975
scott 20 3000
ford 20 3000
allen 30 1600
blake 30 2850
6 개의 행이 선택되었습니다.
--------------------------------------------------
-- 1) 메인쿼리에서 부서번호(e1.deptno)를 읽어서 서브쿼리로 전달
-- 2) 서브쿼리는 메인쿼리에서 받은 부서번호로 평균 급여 계산
-- 3) 다시 메인쿼리는 서브쿼리의 평균 급여보다 큰 급여의 직원 출력🥕 FROM 절에 사용하는 서브쿼리
- 인라인 뷰 라고 합니다
- SELECT 절의 결과를 FROM 절에서 하나의 테이블처럼 사용하고 싶을 때 사용
- 기존 단일 쿼리로는 '테이블에서 각 부서별 최대 연봉' 까지 알 수 있었다면,
- 서브쿼리를 통해서 누가 최대 연봉자인지 확인할 수 있게 되었습니다.
- 기본적으로 FROM 절에는 테이블 명이 오도록 되어있습니다. 그런데 서브쿼리가 FROM 절에 사용되면 동적으로 생성된 테이블인 것처럼 사용할 수 있습니다.
- 인라인 뷰는 SQL 문이 실행될 때만 임시적으로 생성되는 동적인 뷰이기 때문에 데이터베이스에 해당 정보가 저장되지 않습니다.
- 인라인 뷰는 동적으로 조인 방식을 사용하는 것과 같습니다.
SELECT t1.c1,
T2.c1,
T2.c2
FROM t1 T1,
(SELECT c1,
c2
FROM t2) T2
WHERE t1.c1 = T2.c1;즉, FROM 절에 서브쿼리를 사용하면 특정 조건식을 갖는 SELECT 문을 테이블처럼 사용할 수 있습니다.
이를 통해 SELECT 문을 효율적이고 간결하게 작성할 수 있습니다.
이는 마치 가상 테이블, 즉 뷰(view)2와 같은 역할을 한다고 해서 인라인 뷰(inline view)라고도 부릅니다.
뷰
- 테이블은 실제로 데이터를 가지고 있는 반면, 뷰는 실제 데이터를 가지고 있지 않습니다.
- 질의에서 뷰가 사용되면 뷰 정의를 참조해서 DBMS 내부적으로 질의를 재작성하여 질의를 수행합니다.
- 뷰는 실제 데이터를 가지고 있지 않지만, 테이블이 수행하는 역할을 수행하기 때문에 가상 테이블이라고도 합니다.
| 뷰 사용의 장점 | 설명 |
|---|---|
| 독립성 | 테이블 구조가 변경되어도 뷰를 사용하는 응용 프로그램은 변경하지 않아도 된다. |
| 편리성 | 복잡한 질의를 뷰로 생성함으로써 관련 질의를 단순하게 작성할 수 있다. |
| 보안성 | 숨기고 싶은 정보가 존재하는 경우, 뷰를 생성할 때 해당 컬럼을 빼고 생성하여 정보를 숨길 수 있다. |
반응형


댓글