Langchain 시작하기 + VectorDB
앞으로 할 기술스택

랭체인이란 ?
- 초거대 언어모델(LLM)
어플리케이션 개발 프레임워크- 프레임워크?
= 관련 도구 모음
- 프레임워크?
- https://www.langchain.com/


도구 모음을 왜 사용함 ?
- 굳이 안써도 됨
- 따로 갖다가 붙여도 ㄱㅊ
랭체인 말고 없음 ?

근데 왜 랭체인 배움 ?
- 제일 많이 쓰니까
- 지루한 설명
- 문맥 인식: 언어 모델을 문맥 소스(프롬프트 지침, 몇 개의 샷 예시, 응답의 근거가 되는 콘텐츠 등)에 연결합니다.
- 추론: 언어 모델을 사용하여 추론(제공된 컨텍스트에 따라 답변하는 방법, 취해야 할 조치 등)합니다.
- 이 프레임워크는 여러 부분으로 구성되어 있습니다.
- LangChain 라이브러리: 파이썬과 자바스크립트 라이브러리. 수많은 구성 요소에 대한 인터페이스와 통합, 이러한 구성 요소를 체인 및 에이전트로 결합하기 위한 기본 런타임, 체인 및 에이전트의 상용 구현이 포함되어 있습니다.
- LangChain 템플릿: 다양한 작업을 위해 쉽게 배포할 수 있는 참조 아키텍처 모음입니다.
- LangServe: LangChain 체인을 REST API로 배포하기 위한 라이브러리입니다.
- LangSmith: 모든 LLM 프레임워크에 구축된 체인을 디버그, 테스트, 평가, 모니터링할 수 있는 개발자 플랫폼으로 LangChain과 원활하게 통합됩니다.
- LangGraph: LangGraph는 LLM을 사용해 상태 저장형 멀티액터 애플리케이션을 구축하기 위한 라이브러리로, LangChain 위에 구축되어 있으며 함께 사용하도록 고안되었습니다. 여러 계산 단계에 걸쳐 여러 체인(또는 액터)을 순환 방식으로 조정할 수 있는 기능으로 LangChain 표현 언어를 확장합니다.
- LangChain 라이브러리 자체는 여러 가지 패키지로 구성되어 있습니다.
[랭체인 코어](https://github.com/langchain-ai/langchain/blob/master/libs/core): 기본 추상화 및 랭체인 표현식 언어.[랭체인 커뮤니티](https://github.com/langchain-ai/langchain/blob/master/libs/community): 타사 통합.[langchain](https://github.com/langchain-ai/langchain/blob/master/libs/langchain): 애플리케이션의 인지 아키텍처를 구성하는 체인, 에이전트 및 검색 전략입니다.
- LangChain은 언어 모델로 구동되는 애플리케이션을 개발하기 위한 프레임워크입니다. 이를 통해 다음과 같은 애플리케이션을 구현할 수 있습니다:
- 지루한 설명

Streamlit
- 빠르게 개발이 가능하다 - 웹개발관련 지식이 부족해도 쉽게 웹페이지를 만들 수 있다.
- 파이썬에서 분석한 내용을 옮길 필요 없이 바로바로 웹에 띄울 수 있다. + ML/DL 사용가능한 라이브러리들이 많다!
- interactive한 웹 개발이 가능하다.
- 여기 설명 잘나와있습니다
- Python Streamlit 사용법 - 프로토타입 만들기
Python Streamlit 사용법 - 프로토타입 만들기
Python Streamlit에 대한 글입니다 python streamlit tutorial, python streamlit dashboard, python streamlit install, python streamlit vs dash, python dashboard, python streamlit example
zzsza.github.io
Streamlit • A faster way to build and share data apps
Streamlit • A faster way to build and share data apps
Streamlit is an open-source Python framework for machine learning and data science teams. Create interactive data apps in minutes.
streamlit.io
Streamlit Community Cloud • Streamlit
Streamlit • A faster way to build and share data apps
View, collaborate, and manage all your apps in a single place.
streamlit.io
챗 지피티 API
- 비싸다 .
- 돈내기 싫다
- 회사 보안상
- 정보유출우려
인터넷 없이 내 컴퓨터(로컬)에서만 LLM 돌리기
- 라마 2
- 라마 2 경량화 버전
TheBloke/Llama-2-7B-Chat-GGML · Hugging Face
Llama 2 7B Chat - GGML Description This repo contains GGML format model files for Meta Llama 2's Llama 2 7B Chat. Important note regarding GGML files. The GGML format has now been superseded by GGUF. As of August 21st 2023, llama.cpp no longer supports GGM
huggingface.co
VECTOR DB
- 벡터(Vector) = [1, 2, 3, 4, 5]
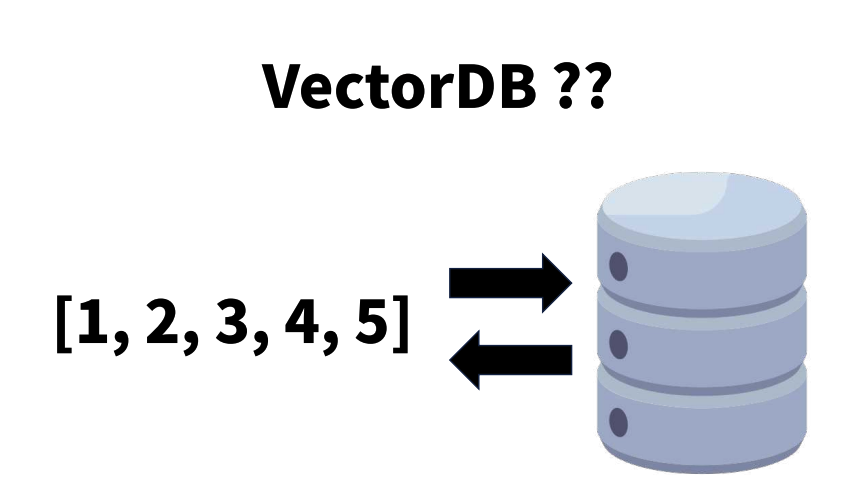
임베딩(Embedding)?
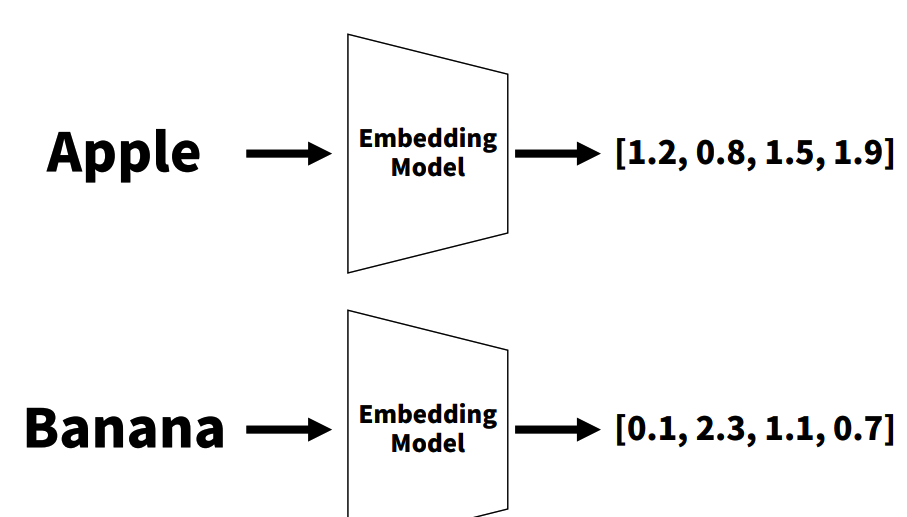
- 데이터(텍스트, 이미지, 오디오 등) → Embedding Model→ [1.2, 0.8, 1.5, 1.9]
-
- RDB → NOSQL → VDB
- 그림 앞의 3개는 좀 느리고 잘 안맞음
- 그래서 나온 개념 → 새로운 데이터가 나왔을때 더 가까운애들 갖고와봐
- 옛날부터 나왔는데 이제야 각광받는중DB 진화
- 아래 설명
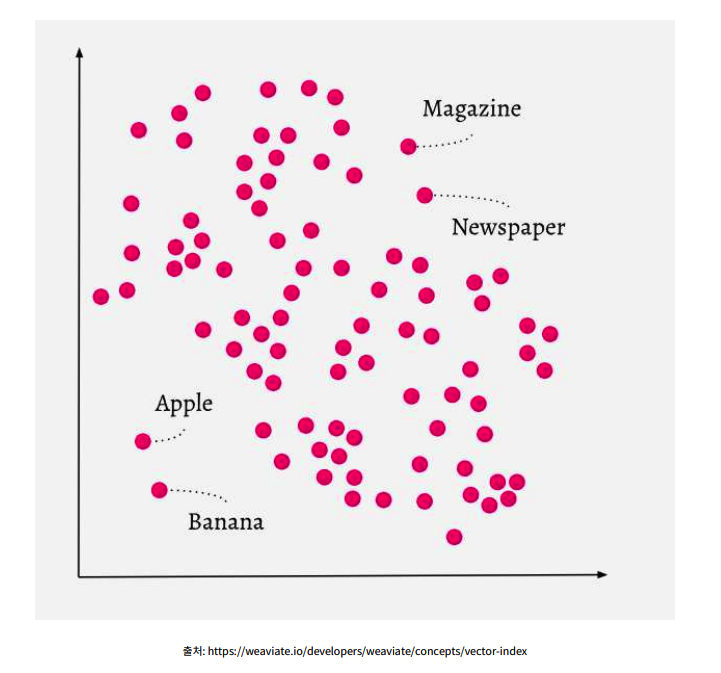
- 사과에 대한 기사 라는 문장 넣으면
- 매거진 이라는 단어랑 비슷~
- 사과 라는 단어랑 비슷 ~
- 사과에 대한 기사 라는 문장 넣으면
- 추가심화
- AI 어플리케이션들은 Vector Embeddings에 의존
- 임베딩은 AI 모델에 의해 생성되며, 많은 수의 속성/피쳐가 있어서 관리하기가 어려움
- AI 및 ML에서 이 피쳐들은 패턴, 관계 및 기본 구조를 이해하는데 필수적인 데이터의 다양한 디멘젼들을 표현
- Pinecone 같은 벡터DB는 이런 임베딩 데이터를 최적화 하여 보관하고 쿼리하기 위해 특화된 DB
- 벡터DB를 통해서 AI에 시맨틱 정보 검색, 장기 메모리 등의 고급 기능들을 구현 가능
- 임베딩 모델을 통해서 인덱싱할 콘텐츠의 벡터 임베딩을 생성
- 벡터 임베딩들을 벡터DB에 삽입. 임베딩이 어디에서 생성되었는지 오리지널 콘텐츠에 대한 레퍼런스를 포함
- 어플리케이션이 쿼리를 하면, 같은 임베딩 모델을 이용하여 쿼리에 대한 임베딩을 생성하고, 이 임베딩으로 DB를 검색해서 비슷한 벡터 임베딩을 찾음
- 이 임베딩들은 오리지널 콘텐츠에 연결되어 있음
- AI 어플리케이션들은 Vector Embeddings에 의존
-

- 주로 이거 4개 사용함
- 추가설명
- Vector Index 와 Vector DB의 차이점
- FAISS(Facebook AI Similarity Search) 같은 벡터 인덱스도 벡터 임베딩 검색을 개선하지만, DB의 기능을 가지고 있지는 않음
- Vector DB는 여러가지 장점을 가짐
- 데이터 관리 기능: 데이터의 삽입, 삭제, 갱신이 쉬움
- 메타데이터 저장 및 필터링: 각 벡터에 대한 메타데이터 저장이 가능
- 확장성: 분산 및 병렬처리 기능을 제공
- 실시간 업데이트 지원
- 백업 및 컬렉션 기능(일부 인덱스만 골라서 백업)
- 에코시스템 연동: ETL(Spark), 분석도구(Tableau, Segment), 시각화(Grafana) 등과 연동. AI 도구와의 연동(LangChain, LlamaIndex, ChatGPT Plugins)
- 데이터 보안 및 접근 권한 관리
- Vector Index 와 Vector DB의 차이점
추가공부
참고할만한 사이트
- 벡터 db
AI 이미지 검색 엔진 만들기 - 벡터 데이터베이스 설명과 Chroma DB 튜토리얼
https://www.youtube.com/c/andreidumitrescu



댓글