수학적 법칙이나 논리적 추론에 따라 인과관계가 형성될 수밖에 없는 당위성(logical imperative)을 구축한다.
Data/Evidence-Oriented
Statistics-Based Approach
통계적 비편향성(Unbiasedness : 모집단의 부분집합을 샘플링 했을 때 샘플 내에서 찾아낸 원인과 결과의 관계가 모집단에서도 비슷하게 나타나는 것)을 바탕으로 인과관계를 정의한다
장점 : 내생성 Endogeneity 를 바탕으로 하기 때문에, 수학적으로 계산할 수 있다. (평가를 위한 통계지표를 비교적 수월하게 만들 수 있음) - 도구변수 같은
단점 : 어떤 데이터를 어떻게 분석해야 하는지, 어떤 요인을 통제해야 하는지 등 데이터 분석의 전략을 제시하지 못한다.
Design-Based Approach
전체를 처치 treatment 집단과 통제 control 집단으로 나누고, 적절한 연구 디자인을 통해 인과추론을 방해하는 선택 편향을 제거하는 방식으로 접근한다.
핵심은 Potential Outcomes Framework - 데이터의 양이나 모형의 복잡도가 아니라, 데이터를 수집하기 전부터 적절한 연구 디자인을 적용했는지 여부가 인과 추론 결과에 큰 영향을 미친다.
장점
데이터 분석의 전략을 제시할 수 있다.
적절한 연구 디자인만 적용할 수 있다면, 인과적 구조에 대한 깊은 이해 없이도 인과효과를 추정할 수 있다.
단점
어떤 인과적 구조, 어떤 메커니즘을 통해서 발생하는지 설명하지 못한다.
Structure-Based Approach
원인과 결과가 서로 얽혀있는 인과 구조를 추정하고자 한다.
장점
데이터 분석의 전략을 제시할 수 있다.
원인 변수가 결과 변수에 영향을 미치는 메커니즘과 인과적 구조를 직접 보여주거나 추정할 수 있다.
단점
인과적 구조를 잘못 산정할 경우 완전히 다른 추론 결과를 얻게될 수 있다.
(따라서 Causal Structure의 구조를 검증하는 것이 중요한 과제가 된다.)
인과관계와 상관관계
인과관계 : 두 변수 중 한쪽이 원인
상관관계 : 비슷한 양상을 보일뿐 - 인과성이 있는지는 모름
가장 먼저 체크해야 할 세 가지 포인트
‘우연의 일치’는 아닌가? (거짓 상관)
우연의 일치? → 우연하게 데이터가 상관관계를 가지는 것
제3의 변수’는 없는가?
제 3의 변수는 ? → 더워서 아이스크림이 잘 팔린건데 , 더워서 해변에 많이 가는거고, 그러다보니 상어에게 많이 물리는건데 불구하고 상어에게 물리는 사람이 많을수록 아이스크림이 잘 팔린다 와 같은 결론을 내는 것
제3의 변수: 원인과 결과 모두에 영향을 주며, 상관관계에 지나지 않는 것을 마치 인과관계가 있는 것처럼 보이게 만드는 성가신 존재. (=‘교란 요인’)
역의 인과관계’는 존재하지 않는가?
역의 인과관계 → 씨앗을 심어서 열매가 난건데 , 열매랑 씨앗을 동시에보고 열매덕분에 씨앗이 생겼다고 생각하는 것
왜?
두 변수가 인과관계에 있다면 다시 원인이 발생했을 때 같은 결과를 얻게 된다. 즉 ‘우연의 일치’, ‘교란 요인’, ‘역의 인과관계’는 존재하지 않는다는 것이다.
한편 두 변수의 관계가 상관관계에 지나지 않는다면, ‘우연의 일치’, ‘교란 요인’, ‘역의 인과관계’ 중 하나가 존재한다. 상관관계의 경우, 그 원인이 다시 일어나도 같은 결과를 얻게 된다고 보기는 어렵다.
인과관계의 존재는 원인이 발생한 ‘사실’의 결과와, 원인이 발생하지 않은 ‘반사실’의 결과를 비교해 증명해야 한다. 문제는 현실에서는 사실은 관찰할 수 있지만 반사실은 관찰할 수 없다는 것인데, 하버드 대학교의 통계학 교수 도널드 루빈(Donald Rubin)은 이를 ‘인과 추론의 근본 문제’라고 불렀다.
에비던스
인터넷에서 찾은 에비던스
책에서의 에비던스
인과관계를 시사하는 근거를 의미하는 용어로 경제학에서 파생됨
강한 에비던스는 인과관계를 정확히 증명할 수 있는 기법을 통해 도출된 것, 약한 에비던스는 인과관계와 상관관계를 오인할 가능성이 있는 기법으로 산출된 것을 가리킴
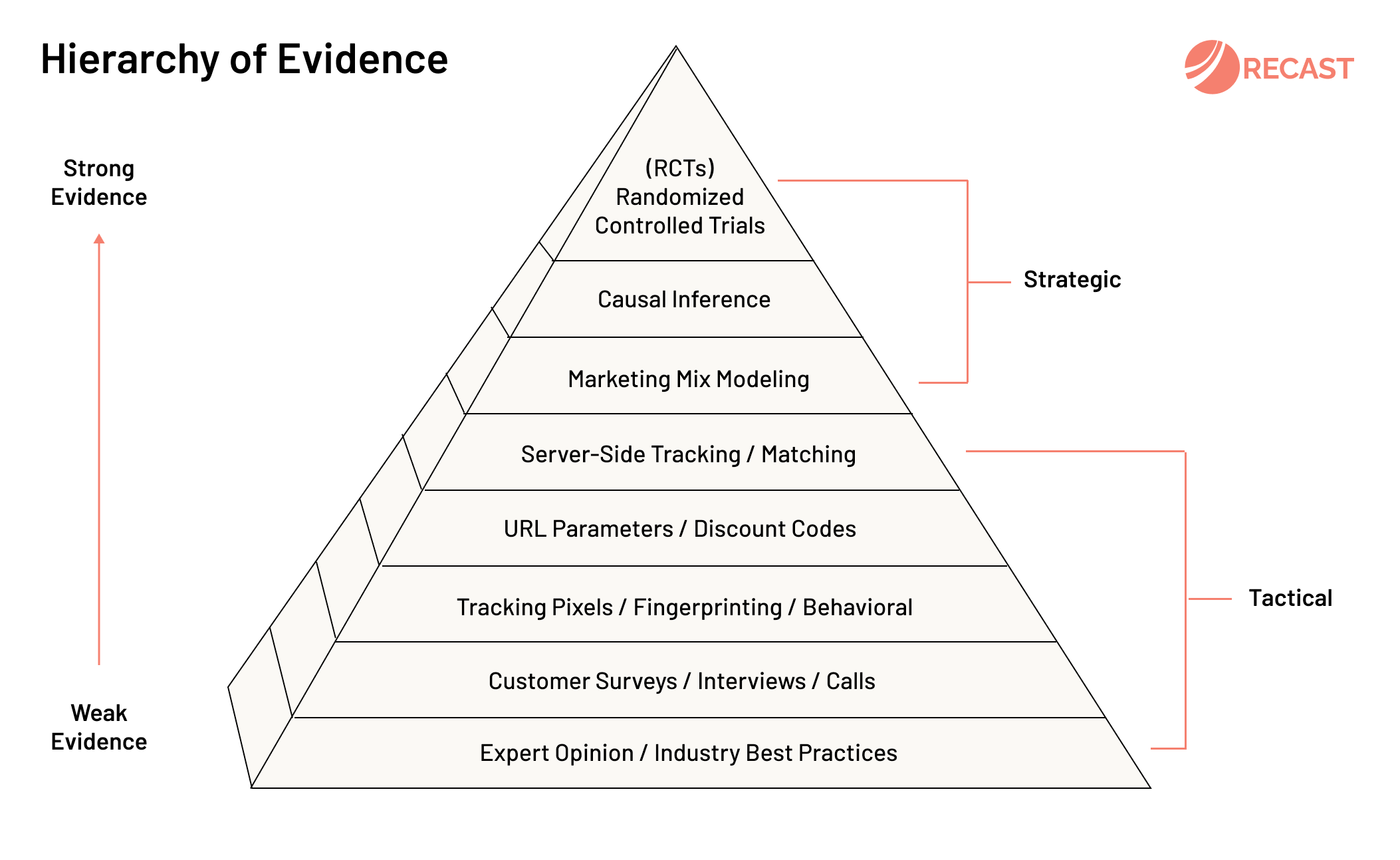
전문가 의견 , 산업의 케이스가 제일 낮은 에비던스 , 책에서는 회귀분석을 제일 낮게본다.
Level of Causal InferenceResearch Design
7
Meta-Analysis
6
Randomized Experiment (RCT)
5
Quasi-Experiment
4
Instrumental Variable
3
“Designed” Regression (w. Causal Diagram)
2
Regression
1
Model-Free Descriptive Statistics
‘반사실 Counterfactual’로 증명하다
반 사실이란 쉽게 얘기해서 평행 세계를 생각해보는 것이다. 위 예시를 예로 들면, 우리가 지금 살고 있는 세계에서는 정부의 지침과 국민들의 성원에 힘업어 백신 접종률 84%를 달성하였다. 그런데 만약 평행 세계가 있다고 가정하고 그 평행 세계에서는 백신 접종률이 44%밖에 안된다고 생각해보는 것이다. 이러한 평행 세계를 반 사실(counterfactual)이라고 한다.
반사실 = 잠재적 결과
멀티버스를 생각해보자
만약 손흥민이 토트넘으로 이적을 하지 않았다면 ?? 토트넘이 손흥민의 축구실력을 높히는데 도움이 되었을까?
근데 반사실은 우리가 알수 없는 데이터 ! = Potential Outcome을 모두 관찰할 수 없다
Treatment 를 받았거나, 받지 않은 상황 중 한 가지만 관찰할 수 있다.
Treatment를 받은 사람들과, 받지 않은 사람들도 나누어서 관찰할 수밖에 없다.
정확한 인과 효과를 알기 위해서는 Counterfactual 이 필요하지만 관찰할 수 없고, 대신 Control 그룹의 정보만 알 수 있다.
따라서 Control 그룹을 최대한 Counterfactual에 가깝게 만들어야 한다.
Control 그룹과 Counterfactual 의 차이가 선택 편향(Selection Bias)으로 나타난다.
현실과 이론의 차이
현실에서는 Treatment가 랜덤하게 배정되지 않고, 각 개인이 Treatment를 선택하게 되는 경우가 많다.
우리가 관측한 Treatment 효과 = 실제 인과 효과 + 선택 편향
선택 편향을 줄일 수 있다면 관찰한 결과로 인과 효과를 추정할 수 있다.
비교 가능하다는 것의 의미
인과 추론이란 선택 편향을 제거하는 과정이다.
Treatment 그룹과 Control 그룹을 최대한 비슷하게 만들어, Counterfactual에 가까운 Control 그룹을 찾을 수 있도록 연구 디자인을 설계해야한다.
RCT(랜덤화 비교 시험)
RCT는 특정한 처리(예: 약물, 치료법, 정책 변경 등)의 효과를 평가하기 위해 사용되는 실험 설계 방법론
RCT는 랜덤하게 선택된 개체들을 실험군과 대조군으로 분류하고, 실험군에만 처리를 적용한 후 두 그룹 간의 결과를 비교하여 처리의 효과를 추정한다.
두 변수의 관계가 인과관계인지 상관관계인지를 밝히는 가장 확실한 방법은 ‘실험’
랜덤화 비교 시험은 ‘실험군이 만약 개입 받지 않았더라면’이라고 가정하는 반사실을 대조군의 데이터로 채우기 위한 실험
‘랜덤화: RCT에서 '랜덤'이란 의미는 실험 대상이 실험군에 배정될 확률이 모든 실험 대상에서 동일하다는 것을 의미
이는 처리의 효과를 한쪽으로 치우치지 않게끔 추정하기 위해서 중요한 단계
실험 대상의 선택이 처리의 결과에 영향을 주는 요인들로부터 독립적이게 만듭니다.
선택 편향: 선택 편향은 실험 대상이 처리에 노출되는 여부가 처리의 결과에 영향을 주는 요인들과 연관되어 있는 경우 발생합니다. 예를 들어, 연구 대상이 자발적으로 처리를 선택하게 되는 경우, 그들의 선택은 그들의 건강 상태, 생활 습관, 사회 경제적 상태 등 다양한 요인들에 의해 영향을 받을 수 있습니다.
이런 요인들은 처리의 결과에도 영향을 미치므로, 실험군과 대조군 간의 비교를 왜곡시킬 수 있습니다. RCT는 랜덤화를 통해 이러한 선택 편향을 제거하려고 합니다
이중맹검: 이중맹검은 실험의 신뢰성을 높이는 기법으로, 실험참가자와 실험을 진행하는 연구자 모두가 어떤 참가자가 실험군이며 어떤 참가자가 대조군인지 모르게 하는 방법입니다. 이렇게 하면 실험 참가자나 연구자의 행동이 결과에 영향을 미치는 것을 방지할 수 있습니다.
‘실험군과 대조군의 차이가 통계적으로 유의미하지 않았다’의 의미
통계적 유의성: '통계적으로 유의미하다'는 표현은 실험군과 대조군 간의 관찰된 차이가 우연에 의해 발생할 확률이 극히 낮다는 것을 의미합니다. 일반적으로, p-값이 0.05 이하인 경우 그 차이는 '통계적으로 유의미하다'고 판단됩니다. 이는 실험군과 대조군 간의 차이가 우연에 의한 변동성 범위 내에 있지 않고, 처리의 효과로 인한 것이라는 더 강력한 증거를 제공합니다.
그 차이가 우연에 의한 오차 범위 내에서 설명할 수 있다는 의미. 바꿔 말하면 관찰된 차이가 우연의 산물일 확률이 5퍼센트 이하일 때 ‘통계적으로 유의미하다’고 하며, 두 그룹의 차이는 오차나 우연으로는 설명할 수 없는 ‘의미 있는 차이’라는 이야기가 된다.
5%라는 값의 의미
많은 사람들이 동전을 던져서 다섯 번 연속 앞면이 나오면 단순한 우연이 아니라 속임수라고 느낀다. 바로 그 감각을 숫자로 산출해낸 값 (125=3.125%215=3.125%)
5%의 의미: "통계적으로 유의미하다"라고 판단하는 기준인 p-값 0.05는 우연에 의한 결과라고 볼 확률이 5% 이하라는 것을 의미합니다. 이는 일반적으로 사용되는 임계값으로, 여기서 5%는 실제로 처리 효과가 없음에도 불구하고 처리 효과가 있다고 잘못 결론 내릴 수 있는 오류(제1종 오류)를 범할 최대 허용 확률을 의미합니다.
즉, ‘통계적으로 유의미하다’는 말은 이 두 그룹 사이의 차이가 우연일 확률이 동전을 다섯 번 던져서 모두 앞면이 나올 확률만큼 낮다는 의미다.
RCT는 비용이 많이 들고, 윤리적 문제를 야기할 수 있으며, 실제로 실행하기 어려운 경우가 많습니다. 따라서 인과추론을 위한 다른 통계적 방법들이 함께 사용되곤 합니다.
자연 실험
랜덤화 비교 시험의 에비던스 수준은 높지만, 막상 실시하는 것은 쉽지 않다. 결국 랜덤화 비교 시험과 같은 인위적인 실험이 어려운 경우, 우리는 이미 존재하는 ‘관찰 데이터’를 이용해 인과관계를 분석해야 함
자연 실험: 연구 대상자들이 법률이나 제도의 변경, 자연재해 등 ‘외생적 쇼크’에 의해 마치 RCT처럼 자연적으로 개입을 받는 그룹(실험군)과 그렇지 않은 그룹(대조군)으로 나뉜 상황을 이용, 인과관계를 검증하는 방법
95% 신뢰구간의 의미: 추정치가 95퍼센트 확률로 이 구간 내에 있다는 것을 시사한다. 이는 같은 연구를 100회 반복하는 실험에서 매회 95퍼센트 신뢰 구간을 추정했을 때, 100회 중 95회의 신뢰 구간은 참값을 포함하고 있다는 것을 의미한다.
이중 차분법 (DID)
개입을 받는 그룹(실험군)과 그렇지 않은 그룹(대조군)의 개입 전후 결과의 차이와, 실험군과 대조군의 차이 이렇게 두 개의 차이로 효과를 추정하는 방법.
DID의 전제 조건
1. 실험군과 대조군은 개입 전 결과의 ‘트렌드’가 같아야(평행해야) 한다. 즉, ‘트렌드’가 비교 가능해야 한다.
2. 개입과 같은 타이밍에 결과에 영향을 줄 만한 다른 변화가 실험군과 대조군에 별개로 발생하지 않아야 한다.
적어도 개입 전에는 ‘비교 가능’해야 한다
추론 방법
실험군과 대조군 각각에서 개입 전과 후, 두 타이밍의 데이터를 수집
첫 번째 차이는 개입 전후의 차이다(이 ‘차이’는 전후 비교설계가 추정하고 있는 효과와 동일하다).
두 번째 차이는 실험군과 대조군의 차이
이 두 개의 차이를 가지고 개입 효과를 추정한다는 의미에서 ‘이중차분법’
안이하게 전후 비교설계를 이용해 정책을 평가하면, 기대한 결과를 얻지 못할 뿐 아니라, 오히려 사회적으로 해악을 끼칠 가능성이 있는 정책을 높이 평가하는 우를 범할 수 있다.
조작 변수법(Instrumental Variable Method)
통계학과 경제학에서 인과관계를 추정하는 데 사용되는 방법 중 하나입니다. 이 방법은 특히 처리(원인)가 결과에 대해 오차항과 상관관계를 가지는 경우, 즉 처리가 선택 편향에 의해 왜곡되는 경우에 유용합니다.
조작 변수: ‘결과에는 직접 영향을 주지 않지만 원인에 영향을 줌으로써 간접적으로 결과에 영향을 주는 제3의 변수’
조작 변수는 원인에만 영향을 주고 결과에는 영향을 주지 않는 제3의 변수를 의미합니다. 이는 원인과 결과 사이의 인과관계를 추정하는 데 사용되는 도구로, 처리가 랜덤화되지 않은 실험에서 랜덤화를 대체하는 역할을 합니다.
조작 변수법: ‘원인에 영향을 주는 것을 통해서만 결과에 영향을 주는 조작 변수’를 이용해 개입을 받는 그룹(실험군)과 그렇지 않은 그룹(대조군)을 비교 가능한 상태로 만드는 방법.
조작 변수는 원인에 영향을 미친다(Relevance condition): 조작 변수가 원인에 대한 실제적인 영향력을 가지고 있어야 합니다. 그렇지 않으면, 조작 변수를 통해 원인과 결과 사이의 인과관계를 식별할 수 없습니다.
조작 변수법의 전제 조건
조작 변수는 원인에는 영향을 미치지만 결과에는 직접 영향을 주지 않아야 한다.
조작 변수는 결과에 직접 영향을 주지 않는다(Exclusion restriction condition): 조작 변수가 결과에 직접적인 영향을 미치지 않아야 합니다.
즉, 조작 변수의 영향이 결과에 도달하는 유일한 경로는 원인을 통한 것이어야 합니다. 이것은 가장 강력하면서도 가장 자주 비판받는 가정입니다. 이 가정이 만족되지 않으면, 조작 변수법을 통한 인과추론은 편향될 수 있습니다.
조작 변수와 결과 모두에 영향을 줄 만한 제4의 변수가 존재하지 않아야 한다.
조작 변수와 결과 모두에 영향을 줄 만한 제4의 변수가 존재하지 않아야 한다(No confounding condition): 이는 조작 변수와 결과 사이에 오차항이 없어야 함을 의미합니다. 이 가정이 위반되면, 조작 변수는 더 이상 유효한 도구가 아니게 됩니다
회귀 불연속 설계(Regression Discontinuity Design, RD)
회귀 불연속 설계란 ?
자의적으로 결정된 컷오프 값을 중심으로 실험군과 대조군으로 갈리는 상황을 이용해 인과 효과를 추정하는 방법
어떤 처리(원인)의 할당이 컷오프 값에 따라 결정되는 경우에 사용됩니다. 컷오프 값 근처에서의 관찰값을 분석함으로써 인과 효과를 추정합니다.
회귀 불연속 설계 RD의 전제조건
컷오프 값 주변에서 결과에 영향을 줄 만한 다른 이벤트가 발생하지 않아야 한다
이 조건은 컷오프 값 주변의 결과가 처리 할당 외의 다른 요인에 의해 왜곡되지 않아야 함을 의미합니다. 다른 이벤트가 발생하면, 회귀 불연속 설계를 통한 인과관계 추정이 왜곡될 수 있습니다.
컷오프 값에 따른 처리 할당이 예측 가능해야 한다
처리 할당이 컷오프 값에 따라 결정되므로, 연구자들은 컷오프 값에 따른 처리 할당을 명확하게 알아야 합니다.
컷오프 값을 조작하거나 선택할 수 없어야 한다
처리 할당이 랜덤이 아닌 경우, 연구 대상이 컷오프 값을 조작하거나 선택할 수 있다면, 선택 편향이 발생할 수 있습니다. 이러한 편향은 인과 추론의 신뢰성을 저하시킬 수 있으므로, 컷오프 값을 조작할 수 없는 상황에서만 회귀 불연속 설계를 사용해야 합니다.
import numpy as np
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
# 임의의 데이터 생성
np.random.seed(0)
N = 1000
cutoff = 0.5
X = np.random.uniform(0, 1, N)
treatment = np.where(X > cutoff, 1, 0)
Y = 2*treatment + X + np.random.normal(0, 0.1, N)
# 데이터 프레임 생성
data = pd.DataFrame({'X': X, 'treatment': treatment, 'Y': Y})
# 컷오프 주변의 데이터만 선택
bandwidth = 0.1
data = data[np.abs(data['X'] - cutoff) <= bandwidth]
# 회귀 모델 적합
data['X_minus_cutoff'] = data['X'] - cutoff
model = sm.OLS(data['Y'], sm.add_constant(data[['X_minus_cutoff', 'treatment']]))
results = model.fit()
# 결과 출력
print(results.summary())
# 그래프 생성
plt.scatter(data['X'], data['Y'])
plt.plot(data['X'], results.fittedvalues, color='red')
plt.xlabel('X')
plt.ylabel('Y')
plt.show()
위의 코드에서, 우리는 임의의 데이터를 생성하고,
컷오프 값 근처의 데이터만 선택하여 회귀 모델을 적합시킵니다.
그런 다음, 회귀 분석의 결과를 출력하고, 데이터와 적합된 회귀선을 그래프로 표시합니다.
매칭법
매칭법: 결과에 영향을 줄만한 공변량을 이용해 대조군에서 실험군과 매우 흡사한 샘플을 찾아내 매칭시켜 비교하는 방법. 공변량이 복숭리 때는 점수화하여 이용하는 경우도 있다(성향 점수 매칭법)
성향점수 매칭 (Propensity Score Matching PSM) : 복수의 공변량을 종합해 점수화한 것으로, ‘실험군으로 분류될 확률’을 의미
매칭법의 전제조건
결과에 영향을 줄 만한 모든 공변량이 수치화된 데이터로 존재해야 한다.
결과에 영향을 줄 만한 모든 공변량이 수치화된 데이터로 존재해야 한다: 이는 모든 중요한 공변량이 데이터에 포함되어 있어야 하며, 이 공변량들이 결과에 영향을 주는 방식을 알고 있어야 함을 의미합니다. 이것을 '조건부 독립 가정'이라고도 합니다.
모든 공변량이 성향 점수 계산에 이용돼야 한다
모든 공변량이 성향 점수 계산에 이용돼야 한다: 이는 성향 점수가 모든 중요한 공변량을 고려하여 계산되어야 함을 의미합니다.
이 방법도 완벽하지 않으며, 중요한 공변량이 누락되거나, 매칭 과정에서 오류가 발생하는 경우 편향된 결과를 얻을 수 있습니다. 따라서 이 방법을 사용할 때는 신중해야 합니다.
회귀 분석
회귀 분석: ‘최적선(데이터 간의 거리 합계가 가장 작아지도록 그은 선)’을 통해 인과관계를 분석하는 방법
최적선의 기울기는 원인이 한 단위 증가했을 때 결과가 어느 정도 변화하는지 보여주는 것으로, ‘인과 효과’를 의미
회귀선의 기울기는 원인이 한 단위 증가했을 때 결과가 얼마나 변하는지를 나타내며, 이것이 인과 효과를 의미합니다.
하지만, 이것이 실제 인과 효과를 의미하는지는 분석의 문맥에 따라 다릅니다. 예를 들어, 회귀 분석이 실험 데이터에서 수행된 경우, 회귀선의 기울기는 종종 인과 효과를 나타냅니다. 그러나, 회귀 분석이 관찰 데이터에서 수행된 경우, 회귀선의 기울기는 인과 효과를 나타내지 않을 수 있습니다. 이는 교란 변수(confounding variables)의 영향 때문입니다.
중회귀 분석으로 교란 요인의 영향을 배제(교란 요인 값이 움직이도록 고정함)한 다음 원인과 결과의 관계를 평가할 수 있다. 드물기는 하지만, 만일 모든 교란 요인의 데이터를 갖고 있다면 중회귀 분석으로 확실하게 인과관계를 증명할 수 있다.
Y = b0 + b1X1 + b2X2 + ... + bn*Xn + e = 기본형태
Y는 예측하려는 종속 변수입니다.
X1, X2, ..., Xn은 독립 변수입니다.
b0는 y절편입니다.
b1, b2, ..., bn은 각각의 독립 변수에 대한 회귀 계수입니다.
e는 모델에서 설명하지 못하는 오차를 나타냅니다.
다중회귀 분석(multiple regression)은 여러 개의 독립 변수를 동시에 고려하여 종속 변수를 예측하는 회귀 분석의 방법입니다.
다중회귀 분석을 사용하면, 교란 변수의 영향을 통제하고 원인과 결과 간의 순수한 관계를 추정할 수 있습니다. 이는 각 독립 변수의 계수가 다른 변수들이 고정되어 있을 때 해당 변수가 종속 변수에 미치는 효과를 나타내기 때문입니다. 그러나, 이 방법도 완벽하지 않으며, 모든 중요한 교란 변수가 모델에 포함되어 있지 않은 경우, 또는 변수들 간에 복잡한 상호작용이 있는 경우에는 편향된 추정을 얻을 수 있습니다.
독립 변수들 사이에 강한 상관 관계가 있는 경우, 다중공선성(multicollinearity) 문제가 발생할 수 있습니다. 이 문제는 회귀 계수의 추정치를 불안정하게 만들며, 이는 잘못된 해석을 초래할 수 있습니다. 따라서 다중 회귀분석을 사용할 때는 독립 변수들 사이의 상관 관계를 체크하고, 필요한 경우 변수 선택이나 차원 축소 기법을 사용하여 문제를 해결해야 합니다.
import statsmodels.api as sm import pandas as pd # 가상의 데이터를 만들어 봅시다. data = { 'Y': [1, 3, 4, 5, 2, 3, 4], 'X1': [2, 4, 6, 8, 10, 12, 14], 'X2': [5, 7, 8, 9, 11, 13, 15], } df = pd.DataFrame(data) # 종속변수 Y와 독립변수 X1, X2를 설정합니다. X = df[['X1', 'X2']] Y = df['Y'] # statsmodels는 자동으로 상수항을 추가하지 않으므로, add_constant 함수를 사용해 상수항을 추가해줍니다. X = sm.add_constant(X) # OLS(최소제곱법) 모델을 만들고, fit() 함수를 호출하여 모델을 학습시킵니다. model = sm.OLS(Y, X) results = model.fit() # 회귀분석 결과를 출력합니다. print(results.summary())
인과 추론의 타당성과 한계
내적 타당성: 두 변수 사이에 인과관계가 있을 확률. 즉, 연구 대상이 된 집단에 재차 동일한 개입을 했을 때 같은 결과가 재현되는 정도를 가리킴
내적 타당성 (Internal Validity): 내적 타당성은 연구 결과가 실제로 인과관계를 보여주는지를 평가하는 척도입니다.
내적 타당성이 높다는 것은, 연구에서 발견된 관계가 실제로 인과관계를 나타낸다고 믿을 수 있는 정도를 의미합니다. 내적 타당성을 높이기 위해서는 교란 변수(confounding variables), 측정 오류(measurement error), 선택 편향(selection bias) 등과 같은 요인들을 최소화해야 합니다.
외적 타당성: 연구 대상과는 다른 집단에 개입했을 때 같은 결과가 재현되는 정도를 의미
외적 타당성은 연구 결과가 다른 상황이나 집단에서도 일반화되어 적용될 수 있는지를 평가하는 척도입니다. 외적 타당성이 높다는 것은, 연구에서 얻은 결론이 다른 상황이나 집단에서도 유사한 결과를 얻을 수 있을 것이라고 예상할 수 있는 정도를 의미합니다. 외적 타당성을 높이기 위해서는 연구 대상을 다양한 배경과 특성을 가진 사람들로 구성하거나, 다양한 상황에서의 실험을 수행해야 합니다.
인과 추론의 한계는 주로 다음과 같습니다.
인과 관계의 방향성: 인과 추론에서는 종종 원인과 결과 간의 방향성을 명확히 파악하기 어려울 수 있습니다. 때로는 원인과 결과가 서로 상호작용하는 경우도 있기 때문입니다.
교란 변수의 통제: 모든 교란 변수를 완벽하게 통제하기 어려운 경우가 많습니다. 이로 인해 인과 관계를 왜곡하거나 잘못된 결론을 도출할 수 있습니다.
인과 관계의 단순화: 현실 세계의 인과 관계는 종종 복잡한 상호작용을 포함하고 있습니다. 하지만 인과 추론에서는 종종 이러한 복잡한 상호작용을 무시하고, 단순한 인과 관계를 찾으려는 경향이 있습니다.
일반화의 어려움: 특정 상황이나 집단에서 얻어진 연구 결과가 다른 상황이나 집단에서도 반드시 성립한다고 보장할 수 없습니다. 이는 외적 타당성에 대한 문제로, 연구의 일반화(generalizability)에 대한 어려움을 나타냅니다. 특히, 문화적, 사회적, 경제적 배경이 다른 집단에서는 동일한 인과관계가 성립하지 않을 수 있습니다.
시간의 흐름과 인과관계: 인과 추론은 시간의 흐름을 고려하지 않는 경우가 많습니다. 즉, 원인이 먼저 일어나고 그 결과가 나중에 일어나야 하는 "시간의 순서"를 고려하지 않는 경우, 잘못된 인과 관계를 도출할 수 있습니다. 이런 경우, 원인과 결과 사이의 상호작용이나, 원인이 시간에 따라 어떻게 변화하는지를 파악하는 데 어려움이 있을 수 있습니다.
인과 추론에 필요한 데이터의 부재: 인과 추론을 위해서는 원인과 결과, 그리고 그 사이를 연결하는 모든 중간 과정에 대한 데이터가 필요합니다. 하지만 현실에서는 이런 데이터를 모두 얻는 것이 어려운 경우가 많습니다. 이로 인해 인과 관계의 정확한 파악이 어려울 수 있습니다.
RCT의 한계
비용
외적 타당성
윤리적 문제
랜덤화 분류 실패
RCT에서 확인된 효과(Efficacy)보다 실제로 전체에 도입했을 때의 효과(Effectiveness)가 작음
관찰 데이터를 이용한 연구에서도 1) 우연의 일치가 아님, 2) 교란요인이 없음, 3) 역의 인과관계 없음 세 가지조건의 충족 여부를 주의 깊게 검토해 증명할 수 있다면 강한 에비던스가 될 수 있다.
인과추론의 공통적인 5단계
원인 파악
결과 파악
세가지 체크포인트 확인: 1) 우연의 일치가 아님, 2) 교란요인이 없음, 3) 역의 인과관계 없음










댓글