반응형

[SQL] 모든 whitespace(탭, 스페이스, 엔터 값 등) 제거
replace (키워드,'바꿀내용','어떻게바꿀건지내용')을
replace (키워드, ' ', '')으로 작성하면 공백만 바뀐다.
모든 화이트 스페이스 제거를 위해서는 (외부에서 오는 데이터는 언제든 이상한 값으로 올수 있기 때문에 )
Regexp_replace (키워드, '\S*', '
로 작성해야 한다.
---
- Oracle 공식문서는 여기
[https://docs.oracle.com/cd/B19306_01/server.102/b14200/functions130.htm](https://docs.oracle.com/cd/B19306_01/server.102/b14200/functions130.htm)

REGEXP_REPLACE는 문자열에서 정규식 패턴을 검색할 수 있도록 하여 REPLACE 함수의 기능을 확장합니다. 기본적으로 이 함수는 정규식 패턴이 나타날 때마다 replace_string으로 교체된 source_char를 반환합니다. 반환된 문자열은 source_char와 동일한 문자 집합에 있습니다. 함수는 첫 번째 인수가 LOB가 아니면 VARCHAR2를 반환하고 첫 번째 인수가 LOB이면 CLOB를 반환합니다.
---
**문법**
regexp_replace() 함수의 구문(Syntax)은 다음과 같다.
```sql
SELECT regexp_replace( string, pattern
[, replacement_string
[, start_position
[, nth_appearance [, match_parameter ] ] ] ] )
FROM table_namesource_char : 대상 문자열
pattern : 정규표현식 패턴
replace_string : 바꿔치기할 문자열
position : 문자열내에서 (패턴을 체크할) 처음 시작 위치
occurrence : 몇번째 일치하는 건지. ( 0 이면 전부 바꿔치기 )
match_param : 'i' (대소문자 무시), 'c' (대소문자 구분)
자주 사용하는 응용편
- "["와 "]" 사이에 문자를 공백 처리하기, 괄호의 정의를 정하고 사이의 내용을 제거하면 됩니다.
**regexp_replace(s, "\\[.*\\]", "")**- 숫자와 문자를 제외하고 모두 제거
**regexp_replace(nm, '[^A-Z0-9 ]', '')**- 공백이 2개 이상인 부분을 제거
**REGEXP_REPLACE('Kontext is a website for data engineers.','[\s]{2,}', '')**- 끝에 문자가 (으로 시작하고)(으로 사작하지 않는) 문자로 끝나는 것
**regexp_replace('The_quick brown fox jumped over the_fence', '_[^_]*$','')**https://nicola-ml.tistory.com/57 참고
“검색할때 인덱스를 타면 빨라진다"
이런 말을 많이 들어보았을 것이다. 그렇다면 인덱스는 무엇인가?
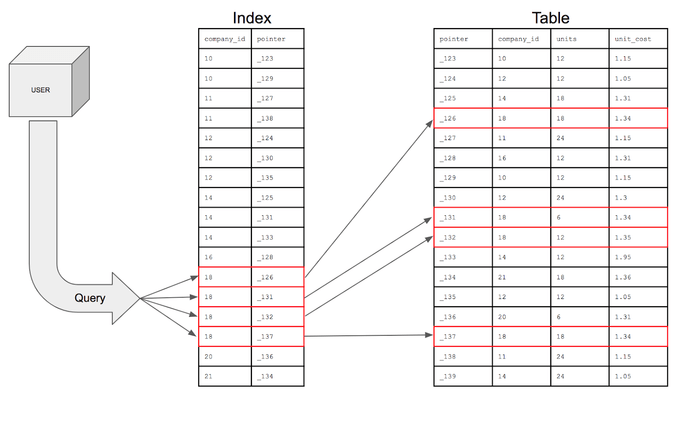
이미지 출처 : https://mangkyu.tistory.com/96
1. 인덱스는 Database 테이블에 대한 검색 성능의 속도를 높여주는 자료 구조 (= 책에서의 목차)
- 즉, 테이블 (= 오브젝트)을 하나 더 생성 하는 것이다. 즉, 인덱스는 테이블과 맵핑되어져 있다. 인덱스에서 먼저 데이터들을 찾은 다음에 그 테이블로 매핑된 곳을 가서 찾아보고 꺼내오는 방식.
- 인덱스를 탄다 = 먼저 인덱스에 저장되어 있는 데이터의 물리적 주소로 가서 데이터를 가져오는 식으로 동작하는 것
- Q. 테이블이 생성되는거랑 속도랑 무슨 상관인가 ?
- A. 인덱스의 저장방식은 인덱스 테이블을 기준으로 sorting 되어서 저장된다.
보통 테이블은 데이터들이 물리적으로 흩어져 저장되어 있는데, 이때 특정 조건에서 데이터를 찾으려면 전체적으로 스캔을 진행해야 한다. 하지만 인덱스는 정렬되어 있기때문에 데이터 검색할때 시작점을 지정해서 그곳으로 부터 스캔 할 수 있다.
- Q. 아직 인덱스를 생성하는 방식이 잘 이해가 가지 않는다.
- 먼저 풀스캔을 하는 이유는 처음에 데이터를 쌓을때 테이블을 만들고 안에 데이터를 쌓게 되면 테이블의 레코드(내용 데이터)는 내부적으로 순서가 없이 뒤죽박죽으로 저장된다. 이러면 전부 다 읽고 (전화번호부에서 전화번호 찾을때 ㄱㄴㄷ 안하고 그냥 전체적으로 쭉 스캔) 찾아와야한다.
- A. 특정 컬럼에 인덱스를 생성하면, 해당 컬럼의 데이터들을 정렬하여 **별도의 메모리 공간**에 데이터의 **물리적 주소**와 함께 저장하는 것이다. 특히 Order by 해서 저장이 된다.
- Q. 그럼 Query에서 Order by 문을 치면 되는것 아닌가?
- Order by는 굉장히 부하가 많이 걸리는 작업이다. 정렬과 동시에 1차적으로 메모리에서 정렬이 이루어지고 메모리보다 큰 작업이 필요하다면 디스크 I/O도 추가적으로 발생된다. 만약 Min Max값을 찾는다면 정렬이 되지 않았을때 쭉 전체 스캔해서 가지고 와야 하지만, 정렬이 되어 있다면 처음 값과 끝 값을 가지고 올 수 있다.2. 테이블의 컬럼 수가 많다면 하나의 블럭에 저장되는 row수가 적어질 것이다. (역도 비슷하다.)
- 그럼 어떤 컬럼을 인덱스로 설정해야 할까 ?
- Where 절에 자주 등장하는 컬럼을 설정하면 효율적
- 그 다음으로는 order by 절에 자주 등장하는 컬럼3. 인덱스의 단점도 있다.
- 만약 레코드의 값이 바뀌어 순서가 바뀐다면 ?
- 인덱스의 값들도 다시 정렬을 해줘야 한다. 그러면 원본 테이블도 수정해야하고 인덱스 테이블도 수정해야 한다.
- 계속 정렬된 상태로 유지해줘야 한다.
- 당연히 인덱스는 저장공간이 필요하다.
- DB 안에서 저장공간이 필요하다. 그러므로 잘 설계해서 필요하면 만들어야 한다.4. 밸런스드 트리 인덱스 구조(B - Tree 인덱스)
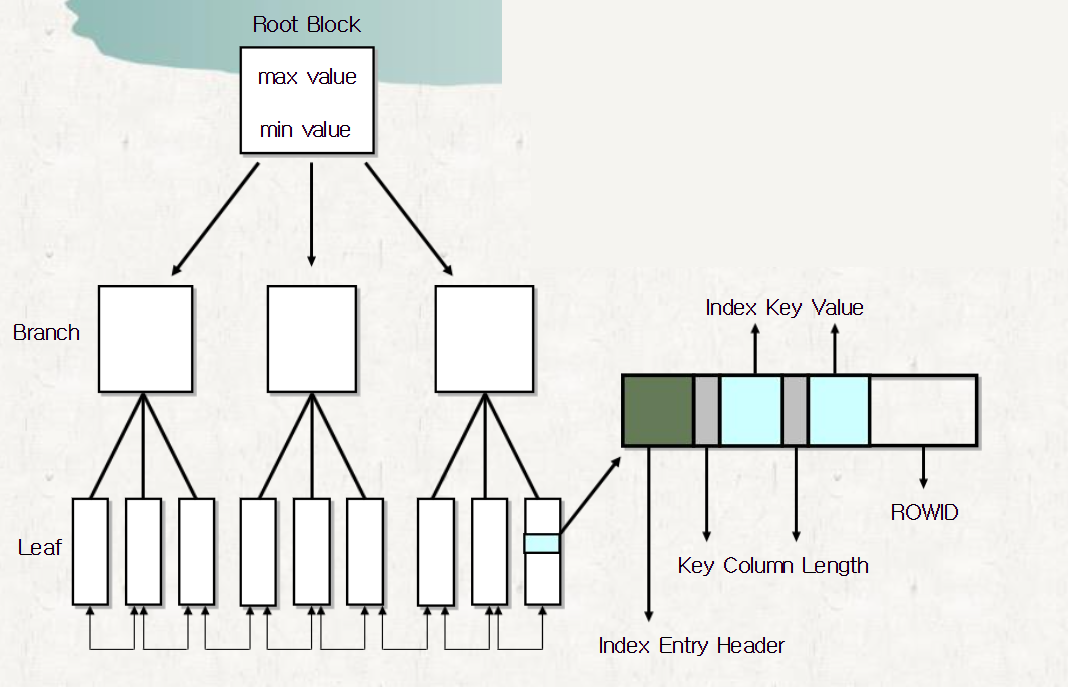
- 구조는 Root(기준) / Branch(중간) / Leaf(말단) Node로 구성
- 특정 컬럼에 인덱스를 생성하는 순간 컬럼의 값들을 정렬하는데,
- 정렬한 순서가 중간 쯤 되는 데이터를 뿌리에 해당하는
ROOT블록으로 지정하고 ROOT블록을 기준으로 가지가 되는BRANCH블록을 정의하며- 마지막으로 잎에 해당하는
LEAF블록에 인덱스의 키가 되는 데이터 + 데이터의 물리적 주소 정보인ROWID를 저장
- 결론적으로 인덱스를 탄다 ⇒ 원하는 데이터 블록주소
ROWID를 찾는 개념이다
- reference
- [DB] 데이터베이스 인덱스(Index) 란 무엇인가?
- https://youtu.be/uO8tL0okg7Q : (ENG SUB) 인덱스를 타면 왜 빨라지는지 아니?
반응형
'Data Analysis > SQL' 카테고리의 다른 글
| 10. [SQL] Query Tuning - 1. 코드컨벤션 지정 (0) | 2022.11.16 |
|---|---|
| 9.[SQL] mysql Week 주 관련 함수 (date 조절), [SQL] Mysql Index 사용법 (0) | 2022.11.16 |
| 7. SQL 에서 Where 1=1은 왜 쓰는걸까, mysql 키워드에서 문자 개수 찾기 (0) | 2022.11.15 |
| 6. RFM Segmentation (SQL) (0) | 2022.11.15 |
| 5. SQL 날짜와 시간, 문자열 다루기, REGEXP(Regular Expression(정규 표현식)), SQL 공부전 처음에 무조건 읽어야 하는 글 ! (0) | 2022.11.15 |


댓글